Proxmox VEにPrometheus, Grafanaを導入した
経緯
昨年から研究室に置いているマシンでProxmox VEを動かしているのだが、先日実家にミニPC(N100, 16GB, 512GB)に設置してProxmox VEを新たに導入した。もともとProxmox VEのWebインターフェースは普段使いでどのくらいCPUやメモリを使用しているかを観察する程度では十分だが複数サーバの健康状態を常に監視するには不十分であり、時系列データを保存しているわけではないのであくまでその時点でのデータしか見れず過去の状態を見ることはできないという点が不便なので、以前から監視ツールであるPrometheusを導入したいと考えていた。
そこで今回メトリクス計測用のVMを立てて、監視したいProxmoxの各ノードに健康状態を返すエンドポイントを立ててくれるExporterを入れて、そのメトリクスをProxmox VE上のVMでPrometheusによって監視し、その時系列データをGrafanaで可視化することにした。
当初の予定としては、Proxmox via PrometheusというGrafanaダッシュボードがいい感じだったので使いたいと考えていて、またPrometheusで監視したデータを時系列データ用のDBであるInfluxDBで管理したいと考えたので、PrometheusとInfluxDBを繋ぐTelegrafを用いて格納するつもりであったのだが、このダッシュボードはデータソースがPrometheusのみでInfluxDBに対応していなかったため、現在はInfluxDBに書き込んでいるもののDB自体は何にも使用していない。ただし、頑張ってデータソースのフォーマットの違いを吸収すれば、このダッシュボードをInfluxDBに対応させること自体はおそらく可能だと思う。
動作環境
ホスト
- Proxmox VE: 8.3.2
- prometheus-pve-exporter: 3.4.7
VM
- Ubuntu Server: 24.04.1
- InfluxDB: 2.7.11
- Telegraf: 1.33.0
- Prometheus: 3.0.1
- Grafana: 11.4.0
ProxmoxホストへのExporterのインストール
以下のサイトを参考にしてprometheus-pve-exporterを使う。
GitHub - prometheus-pve/prometheus-pve-exporter: Exposes information gathered from Proxmox VE cluster for use by the Prometheus monitoring system
Exposes information gathered from Proxmox VE cluster for use by the Prometheus monitoring system - prometheus-pve/prometheus-pve-exporter
github.comPrometheusでProxmox VEのメトリクスを収集する
はじめに ProxmoxのメトリクスをPrometheusで収集するためにexporterのインストールと設定を行う 1. proxmoxのユーザを作成 SSHでrootユーザでproxmoxサーバにログインし、prometheusの読み取り用ユーザを作成する ロールにはPVEAuditorを設定する。GUIからでも作成は可能ですがコマンドのが楽ですね
ryoma.holiday$ sudo pveum user add prometheus@pve -password **** // prometheusユーザのパスワード
$ sudo pveum acl modify / -user prometheus@pve -role PVEAuditor
$ sudo useradd -s /bin/false prometheus
$ sudo apt install python3.11-venv
$ sudo python3 -m venv /opt/prometheus-pve-exporter
$ /opt/prometheus-pve-exporter/bin/pip install prometheus-pve-exporter以下のようにしてユーザ認証の設定を書き込む。
default:
user: prometheus@pve
password: **** // 先ほど設定したprometheusのパスワード
verify_ssl: falseprometheus-pve-exporterをsystemdのサービスとして登録する。
[Unit]
Description=Prometheus Proxmox VE exporter
Documentation=https://github.com/prometheus-pve/prometheus-pve-exporter
[Service]
Restart=always
User=prometheus
ExecStart=/opt/prometheus-pve-exporter/bin/pve_exporter --config.file /etc/prometheus/pve.yml
[Install]
WantedBy=multi-user.target
ここで、ブラウザからhttp://<ProxmoxホストのIPアドレス>/pve?target=<ProxmoxホストのIPアドレス>にアクセスしてみて、以下のような内容が表示されたらExporterがおそらく正常に機能している。
私の場合は、先ほどの手順にあったpveumコマンドを打っていなかったために、Internal Server Errorが表示されていたのだが、sudo journalctl -xeu prometheus-pve-exporterを見るとProxmoxのAPIを叩く権限がないと表示されており、調べたらこの手順が必要なようだった。
# HELP pve_up Node/VM/CT-Status is online/running
# TYPE pve_up gauge
pve_up{id="cluster/Cluster"} 1.0
pve_up{id="node/pve"} 1.0
pve_up{id="qemu/100"} 1.0
pve_up{id="qemu/101"} 1.0
pve_up{id="qemu/102"} 1.0
pve_up{id="qemu/103"} 0.0
pve_up{id="qemu/104"} 0.0
...監視用VMへのInfluxDB, Telegraf, Prometheus, Grafanaの導入
まず、監視用VMを用意する。今回はサーバの性能にそこまで余裕があるわけではないのでUbuntu-24.04-Serverを利用した。また、InfluxDBは結果的に使っていないのでProxmox via Prometheusのダッシュボードを使うだけであれば、InfluxDBとTelegrafのインストールは不要である。
InfluxDBのインストール
以下のようにaptリポジトリを追加してInfluxDBをインストールする。
$ wget -qO- https://repos.influxdata.com/influxdb.key | sudo apt-key add -
$ echo "deb https://repos.influxdata.com/ubuntu focal stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
$ sudo apt update && sudo apt install influxdb -yここで、ブラウザからhttp://<VMのIPアドレス>:8086にアクセスして、ユーザ登録を行いトークンを発行する。
その後、CLIかLoadDataタブののBucketsからPrometheus用のバケットを作成したら、TelegrafからPrometheusのデータを書き込む準備が完了する。
Telegrafのインストール
InfluxDBと同じリポジトリにあるのでそのままインストールする。
$ sudo apt install telegraf -y以下のような内容を設定ファイルに書き込む。
[[inputs.prometheus]]
urls = ["http://localhost:9090/metrics"]
interval = "5s"
[[outputs.influxdb_v2]]
urls = ["http://localhost:8086"]
token = "<InfluxDBのトークン>"
organization = "Organizationの名前"
bucket = "Bucketの名前"書き込んだ設定をテスト実行してエラーが出なければsystemdにサービスとして登録する。
$ sudo telegraf --test --config /etc/telegraf/telegraf.conf
$ sudo systemctl enable telegraf
$ sudo systemctl start telegrafここまでが成功していればブラウザ上でInfluxDBのDashboardやData Explorerからデータの内容を見れるようになる。
Prometheusのインストール
以下のようにしてPrometheusのバイナリをダウンロード、インストールする。本当ならばapt, snapパッケージを使った方がメンテナンスの観点から良いと思われる。
$ wget https://github.com/prometheus/prometheus/releases/latest/download/prometheus-*.linux-amd64.tar.gz
$ tar -xvf prometheus-*.linux-amd64.tar.gz
$ sudo mv prometheus-* /usr/local/prometheus
$ sudo ln -s /usr/local/prometheus/prometheus /usr/local/bin/prometheus
$ sudo ln -s /usr/local/prometheus/promtool /usr/local/bin/promtool
$ sudo mkdir /etc/prometheus
$ sudo mkdir -p /var/lib/prometheus
$ sudo cp /usr/local/prometheus/prometheus.yml /etc/prometheus/prometheusもVMのsystemdのサービスに登録しておく。
[Unit]
Description=Prometheus Monitoring System
Wants=network-online.target
After=network-online.target
[Service]
User=root
ExecStart=/usr/local/bin/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus
[Install]
WantedBy=multi-user.target
Prometheus用の設定ファイルにExporterの情報を書き込む。なお、私の環境ではTailscaleをホストとVMの両方に入れており、DNSの名前解決もそれで行なっている。
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "pve"
dns_sd_configs:
- names:
- "<Proxmoxホストのドメイン>"
type: "A"
port: 9221
metrics_path: /pve
params:
module: [default]
cluster: ['1']
node: ['1']
remote_write:
- url: "http://localhost:8086/api/v2/write?org=<Organizationの名前>&bucket=<先ほど作成したバケットの名前>"
authorization:
credentials: <先ほど発行したInfluxDBのトークン>以下のようにして、設定ファイルをテストして認証などがうまく通りそうか確認したら、systemdにサービスとして登録して起動し、journalctlを見てエラーが出ていないか確認しておく。
$ sudo prometheus --config.file=/etc/prometheus/prometheus.yml --test
$ sudo systemctl daemon-reload
$ sudo systemctl enable prometheus
$ sudo systemctl start prometheus
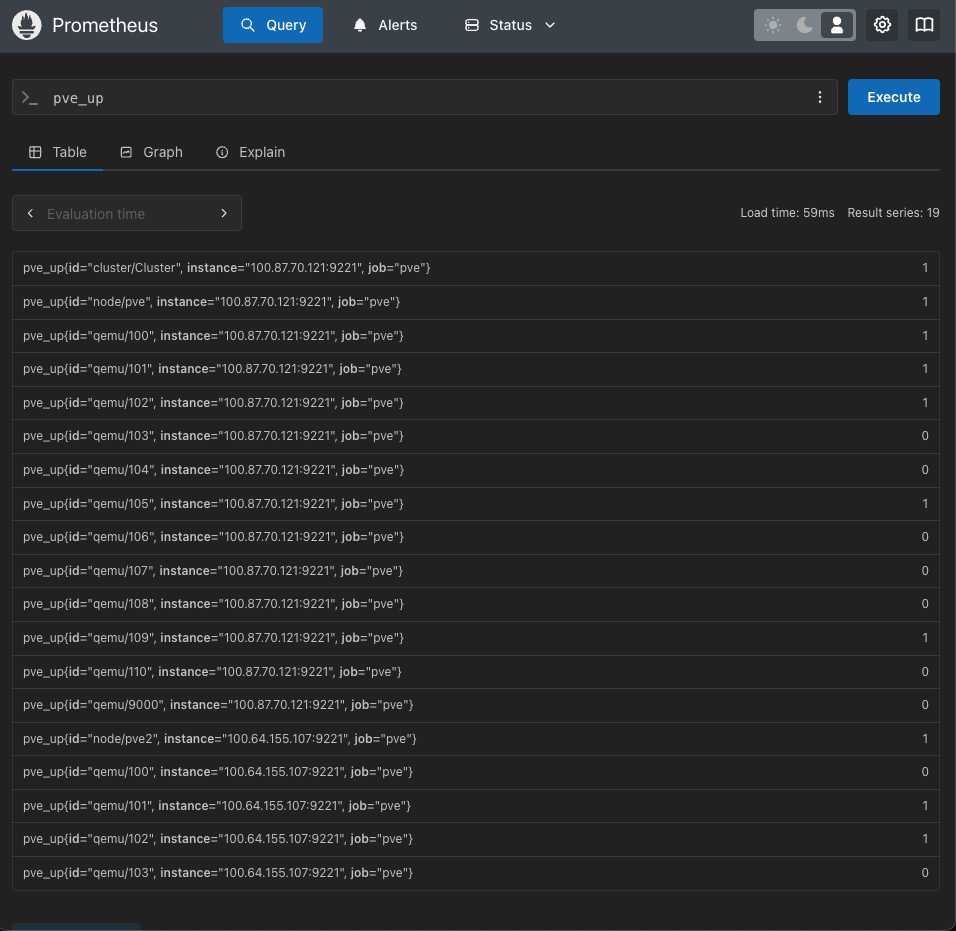
$ sudo journalctl -xeu prometheusブラウザからhttp://<VMのIPアドレス>:9090にアクセスして、pve_upなどのクエリを叩いて、正常に情報が取得できればここまでは正常に動作している。
Grafanaのインストール
以下のようにaptリポジトリを追加してインストールして、systemdにサービスとして登録する。
$ wget -qO- https://apt.grafana.com/gpg.key | sudo apt-key add -
$ echo "deb https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
$ sudo apt update && sudo apt install grafana -y
$ sudo systemctl enable grafana-server
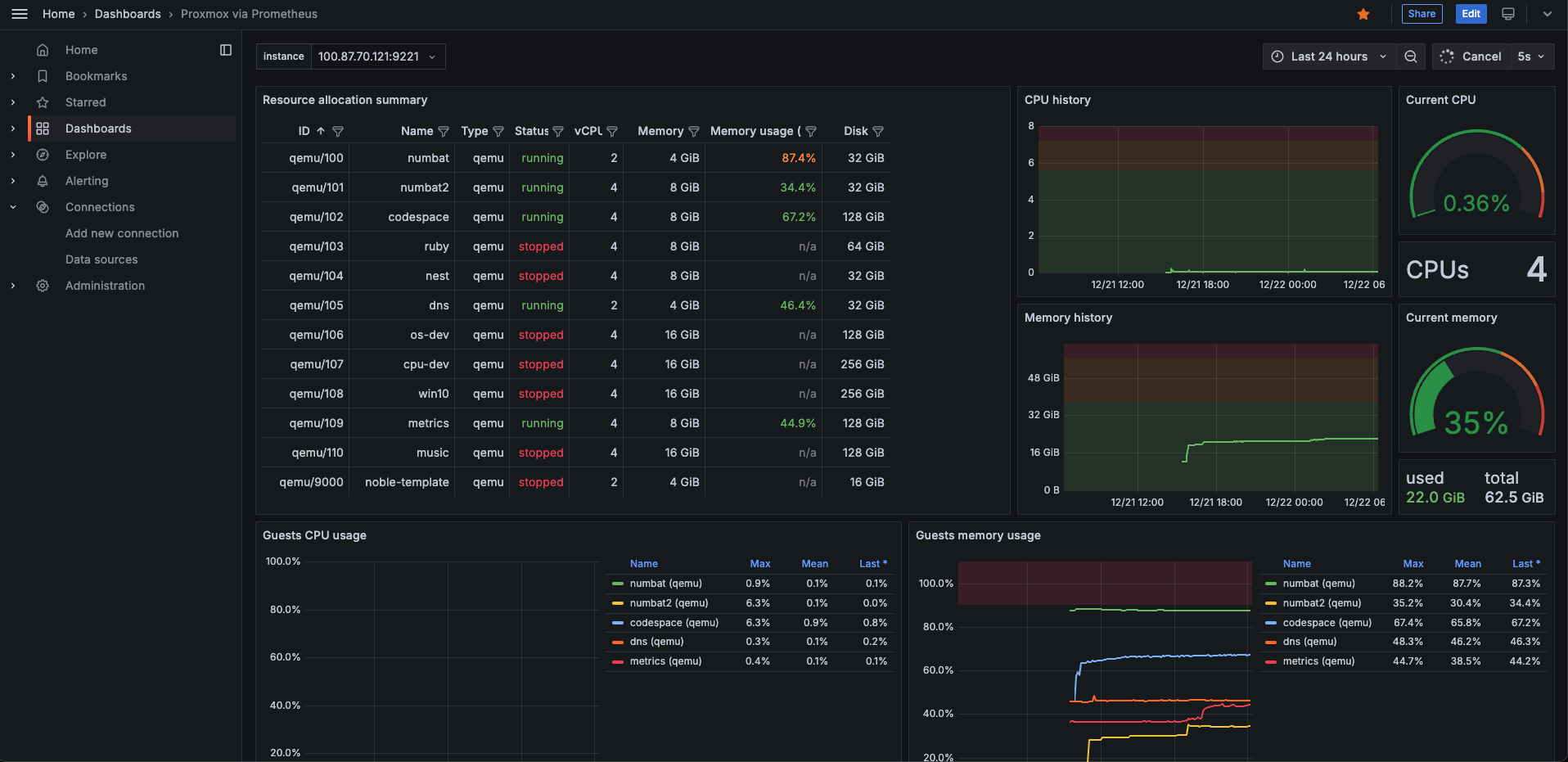
$ sudo systemctl start grafana-serverブラウザからhttp://<VMのIPアドレス>:9221にアクセスして、DataSourcesからprometheusもしくはinfluxdbを追加して、Build a dashboardから構築したいダッシュボードのIDを入力してJSONを穴埋めして読み込むことで、最終的に以下のようなGrafanaダッシュボードが表示された。
感想
今回は、VM上で色々なリポジトリを追加したり、バイナリをダウンロードしたりして何個かのソフトウェアをインストールしたが、このうちいくつかはDockerコンテナで動かすこともできるので、頑張れば全部ホスト上でコンテナのみで動かすことも可能だと思われる。しかし、Proxmoxを使っている以上簡単にVMを生やせるという利点を最大限活かしてこのような構成にした。これによって今後さらに運用するマシンが増えたとしてもそれぞれの健康状態を常に監視することができるようになりとても便利である。